📖 数理统计 (Mathematical Statistics)
本模块持续收录数理统计相关的核心基础概念。
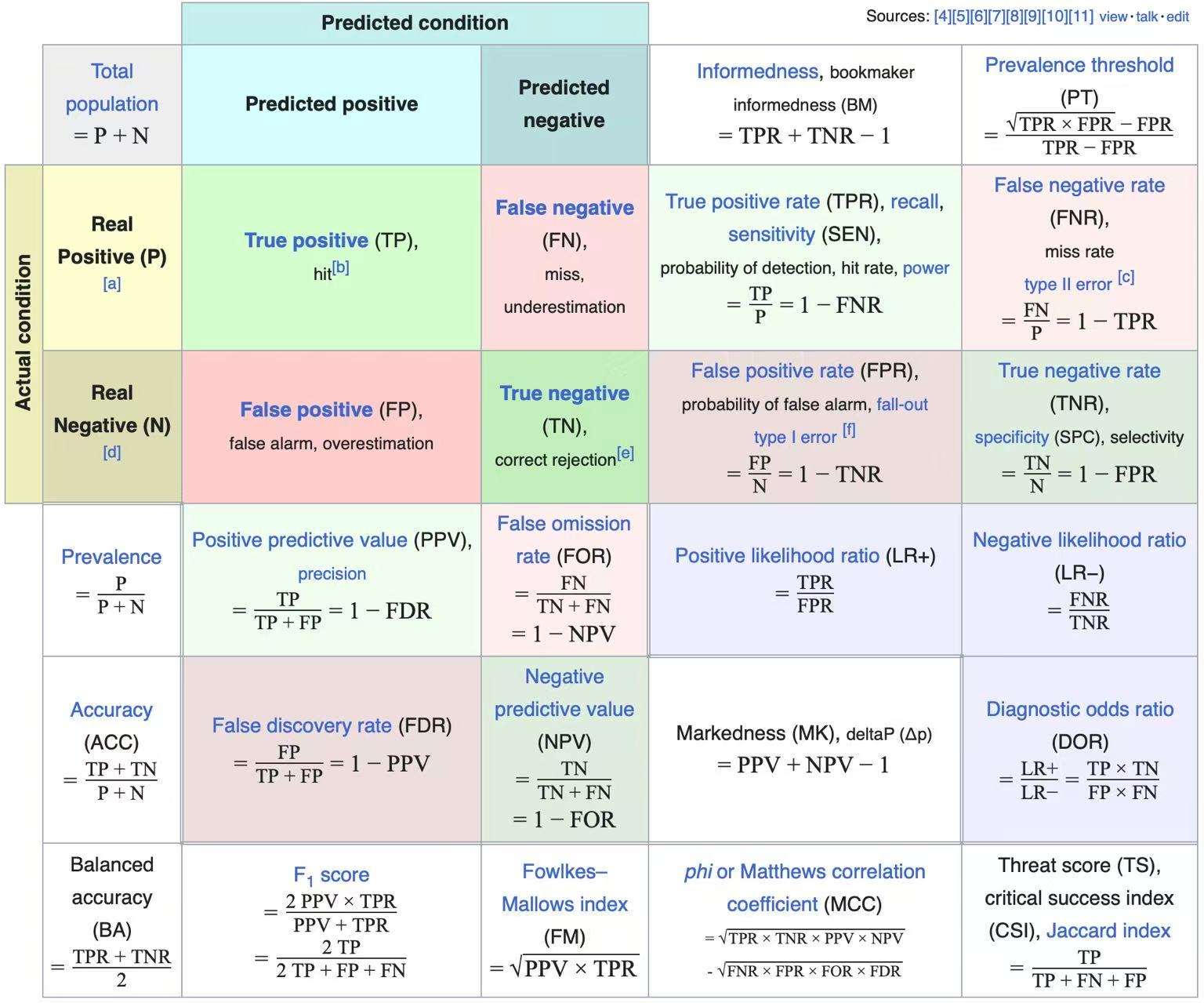
1. 假设检验与混淆矩阵 (Hypothesis Testing)
在频率学派的 Neyman-Pearson 框架下,假设检验本质上是一个基于样本对真实参数空间进行二元决策的过程。
假设检验混淆矩阵 (Confusion Matrix)
| 真实状态 \ 模型预测 | 接受 \(H_0\) (Do not reject) | 拒绝 \(H_0\) (Reject, Discover) |
|---|---|---|
| \(H_0\) 为真 (Null is True) | ✅ 正确推断 (True Negative, \(1-\alpha\)) | ❌ 第一类错误 (False Positive, \(\alpha\)) |
| \(H_1\) 为真 (Alt is True) | ❌ 第二类错误 (False Negative, \(\beta\)) | ✅ 统计功效 (True Positive, Power: \(1-\beta\)) |
核心概念速查
第一类错误 (Type I Error / False Positive)
- 定义:原假设 \(H_0\) 为真,却被错误地拒绝了。即弃真错误(假阳性)。
- 数学表达:\(\alpha = P(\text{Reject } H_0 \mid H_0 \text{ is True}) = \frac{FP}{FP+TN}\)
- 别名:检验的显著性水平 (Significance Level)。在经典统计中,我们通常首先严格控制 \(\alpha\)(如设定为 \(0.05\))。
第二类错误 (Type II Error / False Negative)
- 定义:备择假设 \(H_1\) 为真,却没有能够拒绝 \(H_0\)。即取伪错误(假阴性)。
- 数学表达:\(\beta = P(\text{Accept } H_0 \mid H_1 \text{ is True}) = \frac{FN}{TP+FN}\)
统计功效 (Statistical Power)
- 定义:备择假设 \(H_1\) 为真时,正确拒绝 \(H_0\) 的概率。即检验出真实效应的能力。
- 数学表达:\(\text{Power} = 1 - \beta = P(\text{Reject } H_0 \mid H_1 \text{ is True}) = \frac{TP}{TP+FN}\)
- 直觉:在给定 \(\alpha\) 的前提下,我们希望寻找能够使 Power 最大化的检验方法(即 UMP 检验, Uniformly Most Powerful test)。
p-value (p 值)
- 定义:在原假设 \(H_0\) 为真的条件下,观察到当前样本统计量(或比其更极端情况)的概率。
- 避坑:p 值绝对不是“原假设为真的概率”(即 \(p \ne P(H_0 \mid \text{Data})\))。它反映的是数据与原假设的不一致程度。p 值越小,拒绝 \(H_0\) 的理由越充分。
现代前沿:多重检验与 FDR 控制
在现代高维统计中,我们往往需要同时进行成千上万次检验。此时传统的 \(\alpha\) 控制会彻底失效。
多重检验的问题 (The Multiple Testing Problem)
假设我们独立测试了 \(m\) 个完全无效的因子(即 \(m\) 个 \(H_0\) 均成立),设单次检验的显著性水平为 \(\alpha = 0.05\)。
那么至少犯一次第一类错误的概率(Family-Wise Error Rate, FWER)为:
当 \(m = 100\) 时,\(\text{FWER} \approx 0.994\)。这意味着只要测试足够多的因子,必然会挖掘出看似显著的“伪信号”。这就引入了 FDR 的概念。
FDR (False Discovery Rate) 错误发现率
由 Benjamini 和 Hochberg 在 1995 年提出,是高维推断的核心。
- 定义:在所有被拒绝的原假设(即所有声称有显著效应的发现 \(R\))中,错误拒绝(即第一类错误 \(V\))所占比例的期望值。
- BH 过程 (Benjamini-Hochberg Procedure):
- 将 \(m\) 个假设的 p 值从小到大排序:\(p_{(1)} \le p_{(2)} \le \dots \le p_{(m)}\)。
- 找到最大的整数 \(k\),使得 \(p_{(k)} \le \frac{k}{m} \alpha\)。
- 拒绝前 \(k\) 个原假设(即 \(H_{(1)}, \dots, H_{(k)}\))。
- 定理:在独立性(或正相依)假设下,该过程能够严格控制 FDR \(\le \alpha\)。
2. 次序统计量 (Order Statistics)
设 \(X_1, X_2, \dots, X_n\) 是取自总体分布 \(F(x)\) 及概率密度 \(f(x)\) 的 i.i.d. 样本。将其按升序排列为 \(X_{(1)} \le X_{(2)} \le \dots \le X_{(n)}\),则称 \(X_{(k)}\) 为第 \(k\) 阶次序统计量。
核心分布公式
单个阶统计量的概率密度 (PDF of \(X_{(k)}\))
第 \(k\) 阶次序统计量 \(X_{(k)}\) 的概率密度函数为:
直观推导:多项分布视角 (Heuristic Derivation)
考虑在 \(x\) 附近的一个微小区间 \([x, x+dx]\)。\(X_{(k)}\) 落在该区间的事件等价于:
-
恰好有 1 个 样本落在 \([x, x+dx]\),概率约为 \(f(x)dx\)。
-
恰好有 \(k-1\) 个 样本落在 \((-\infty, x)\),概率为 \([F(x)]^{k-1}\)。
-
剩余的 \(n-k\) 个 样本落在 \((x+dx, \infty)\),概率为 \([1-F(x)]^{n-k}\)。
利用多项系数进行排列组合,总方案数为 \(\frac{n!}{(k-1)! \cdot 1! \cdot (n-k)!}\)。将所有项相乘并约去 \(dx\),即得上述 PDF 公式。
极大值与极小值的分布 (Special Cases)
在可靠性工程和极值理论中最为常用:
-
最小值 \(X_{(1)}\):\(f_{(1)}(x) = n[1-F(x)]^{n-1} f(x)\)
-
最大值 \(X_{(n)}\):\(f_{(n)}(x) = n[F(x)]^{n-1} f(x)\)
重要性质与结论
联合分布 (Joint Distribution)
所有次序统计量的联合概率密度函数为:
(直觉:这相当于将原样本的联合密度在有序空间上进行了 \(n!\) 倍的“堆叠”)。
均匀分布的桥梁作用 (The Uniform Connection)
设 \(U_{(k)}\) 是来自 \(U(0, 1)\) 的次序统计量,则:
-
Beta 分布:\(U_{(k)} \sim \text{Beta}(k, n-k+1)\)。
-
期望与方差:\(E[U_{(k)}] = \frac{k}{n+1}\),这对理解分位数(Quantile)的估计非常重要。
-
概率积分变换:对于任何连续分布 \(F(x)\),有 \(F(X_{(k)}) \overset{d}{=} U_{(k)}\)。
多个次序统计量的联合分布 (Joint Distributions)
在非参数推断和生存分析中,我们经常需要研究某几个特定位次的观测值之间的关系。
任意两个次序统计量的联合密度 (\(i < j\))
设 \(1 \le i < j \le n\),则 \(X_{(i)}\) 和 \(X_{(j)}\) 的联合概率密度函数为:
其中 \(u < v\),否则密度为 0。
多项式逻辑推导 (Multinomial Heuristic)
想象 \(n\) 个样本点被划分为 5 个不同的区间:
-
\((-\infty, u)\):包含 \(i-1\) 个点,概率 \(F(u)\)。
-
\([u, u+du]\):包含 1 个点(即 \(X_{(i)}\)),概率 \(f(u)du\)。
-
\((u+du, v)\):包含 \(j-i-1\) 个点,概率 \(F(v)-F(u)\)。
-
\([v, v+dv]\):包含 1 个点(即 \(X_{(j)}\)),概率 \(f(v)dv\)。
-
\((v+dv, \infty)\):包含 \(n-j\) 个点,概率 \(1-F(v)\)。
根据多项分布的概率公式,排列组合数即为 \(\frac{n!}{(i-1)! 1! (j-i-1)! 1! (n-j)!}\)。将各区间的概率及其对应的幂次相乘,约去 \(du, dv\),立得上述公式。该逻辑可推广至任意 \(k\) 个次序统计量的联合分布。
极差与中位数
样本极差 (Sample Range) 的分布
定义极差 \(R = X_{(n)} - X_{(1)}\)。对于 \(U(0, 1)\) 分布,极差的 PDF 为:
(推导需要先写出 \(X_{(1)}\) 和 \(X_{(n)}\) 的联合分布,再做变量代换)。
核心推导步骤:从联合分布到边际分布
第一步:写出 \(X_{(1)}\) 和 \(X_{(n)}\) 的联合分布 令上述联合公式中的 \(i=1, j=n\),得到:
第二步:变量代换 (Bivariate Transformation) 引入极差 \(R\) 和辅助变量(通常选最小观测值)\(V\):
计算雅可比行列式:\(|J| = \left| \frac{\partial(u, v)}{\partial(r, v)} \right| = \det \begin{pmatrix} 0 & 1 \\ 1 & 1 \end{pmatrix} = |-1| = 1\)。
第三步:求 \(R\) 和 \(V\) 的联合密度
第四步:对 \(V\) 积分求 \(R\) 的边际密度
渐近性质 (Asymptotic Property)
当 \(n \to \infty\) 时:
-
样本中位数:在一定条件下趋于正态分布(基于中心极限定理的变体)。
-
样本极值:趋于三种极值分布之一(Gumbel, Fréchet, 或 Weibull),这是极值理论(EVT)的核心。